Teknisk beskrivning av AI
Den tekniska beskrivningen av AI ger dig en översiktlig introduktion till vad som menas med artificiell intelligens (AI). Vi förklarar olika begrepp och beskriver de olika processerna för hur data bearbetas och används i en AI-modell.
Det här är den tekniska delen av vägledningen om GDPR och AI. Den vänder sig i första hand till jurister som vill öka sina kunskaper om AI. Här kan du läsa den juridiska delen av vägledningen.
Innehåll
Introduktion till AI
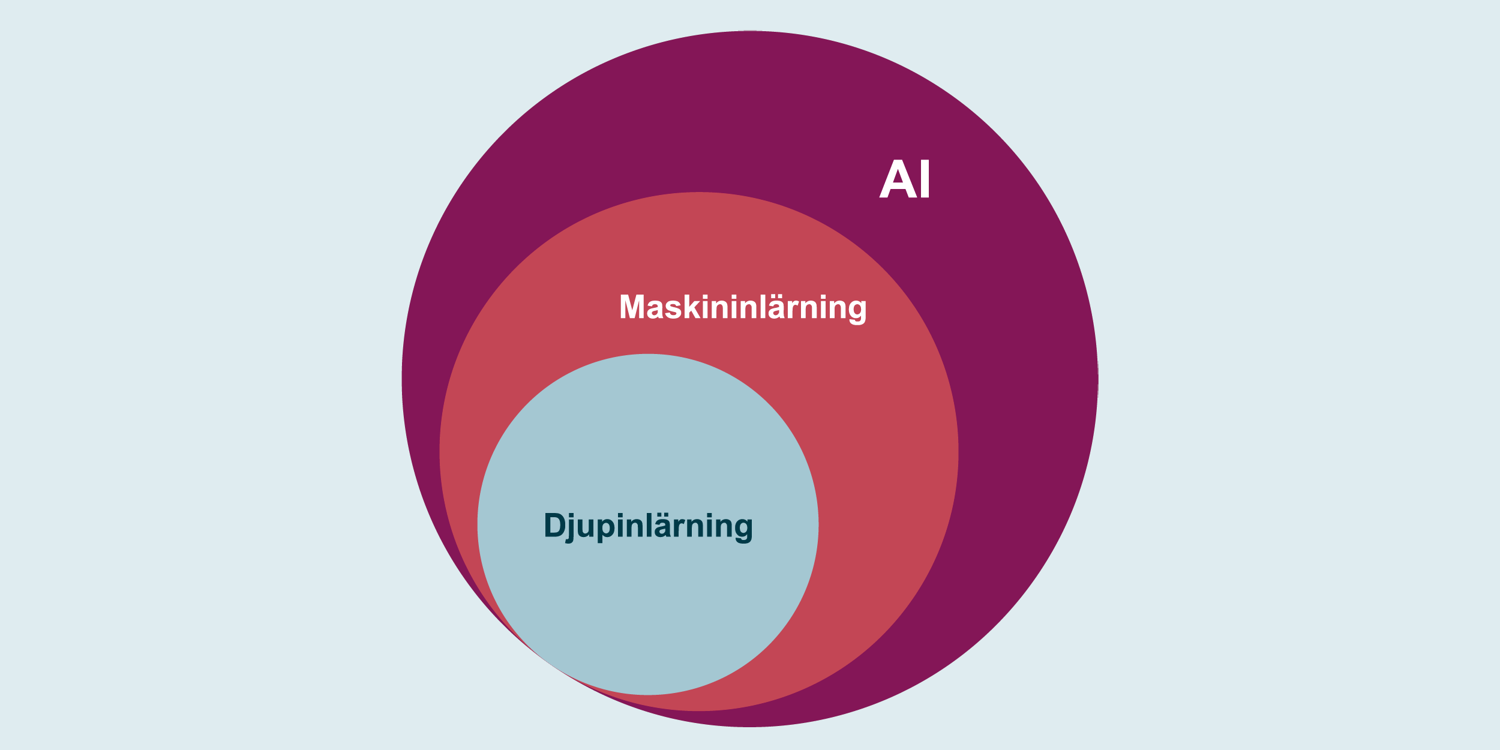
Det finns ingen entydig eller allmänt vedertagen definition av AI. AI är inte heller en särskild teknik, utan omfattar flera olika typer av tekniker, som maskininlärning och djupinlärning. Begreppen används ofta synonymt, men är inte samma sak.
AI definieras snarare utifrån utmärkande drag i kapaciteten eller funktionen. Djupinlärning, som är en form av maskininlärning, är till exempel uppbyggd på ett sätt som liknar den mänskliga hjärnans neuronnät.
Bilden visar hur begreppen förhåller sig till varandra.
Senast uppdaterad: 3 februari 2025